

AMDGPU crash on specific webpage with FF on Linux - reproducable
I am experiencing intermittent but frequent AMDGPU crashes when displaying my homeassistant Lovelace dashboard in Firefox. This issue does not occur in FF under Windows (dual boot). Issue occurs only on this web page and when tab is active. When issue occurs GUI becomes unresponsive for a few seconds and comes back again.
Chromium and homeassistant compananion app Butler do not have this issue.
Fedora Linux 41 (Workstation Edition) Lenovo Yoga Pro 7 14APH8 AMD Ryzen™ 7 7840HS with Radeon™ 780M Graphics × 16 FF Version 132.0.1 (64-bit)
nov 29 13:02:35 ltguido23 kernel: amdgpu 0000:63:00.0: amdgpu: ring gfx_0.0.0 timeout, signaled seq=1236936, emitted seq=1236938 nov 29 13:02:35 ltguido23 kernel: amdgpu 0000:63:00.0: amdgpu: Process information: process firefox pid 4257 thread firefox:cs0 pid 4361 nov 29 13:02:35 ltguido23 kernel: amdgpu 0000:63:00.0: amdgpu: GPU reset begin! nov 29 13:02:36 ltguido23 wpa_supplicant[1403]: wlp1s0: CTRL-EVENT-SIGNAL-CHANGE above=1 signal=-51 noise=9999 txrate=585000 nov 29 13:02:37 ltguido23 kernel: amdgpu 0000:63:00.0: amdgpu: MES failed to respond to msg=REMOVE_QUEUE nov 29 13:02:37 ltguido23 kernel: [drm:amdgpu_mes_unmap_legacy_queue [amdgpu]] *ERROR* failed to unmap legacy queue nov 29 13:02:37 ltguido23 kernel: [drm:gfx_v11_0_hw_fini [amdgpu]] *ERROR* failed to halt cp gfx nov 29 13:02:37 ltguido23 kernel: amdgpu 0000:63:00.0: amdgpu: Dumping IP State nov 29 13:02:37 ltguido23 kernel: amdgpu 0000:63:00.0: amdgpu: Dumping IP State Completed nov 29 13:02:37 ltguido23 kernel: amdgpu 0000:63:00.0: amdgpu: MODE2 reset nov 29 13:02:37 ltguido23 kernel: amdgpu 0000:63:00.0: amdgpu: GPU reset succeeded, trying to resume nov 29 13:02:37 ltguido23 kernel: [drm] PCIE GART of 512M enabled (table at 0x00000080FFD00000). nov 29 13:02:37 ltguido23 kernel: amdgpu 0000:63:00.0: amdgpu: SMU is resuming... nov 29 13:02:37 ltguido23 kernel: amdgpu 0000:63:00.0: amdgpu: SMU is resumed successfully! nov 29 13:02:37 ltguido23 kernel: [drm] DMUB hardware initialized: version=0x08004500 nov 29 13:02:38 ltguido23 kernel: amdgpu 0000:63:00.0: amdgpu: ring gfx_0.0.0 uses VM inv eng 0 on hub 0 nov 29 13:02:38 ltguido23 kernel: amdgpu 0000:63:00.0: amdgpu: ring comp_1.0.0 uses VM inv eng 1 on hub 0 nov 29 13:02:38 ltguido23 kernel: amdgpu 0000:63:00.0: amdgpu: ring comp_1.1.0 uses VM inv eng 4 on hub 0 nov 29 13:02:38 ltguido23 kernel: amdgpu 0000:63:00.0: amdgpu: ring comp_1.2.0 uses VM inv eng 6 on hub 0 nov 29 13:02:38 ltguido23 kernel: amdgpu 0000:63:00.0: amdgpu: ring comp_1.3.0 uses VM inv eng 7 on hub 0 nov 29 13:02:38 ltguido23 kernel: amdgpu 0000:63:00.0: amdgpu: ring comp_1.0.1 uses VM inv eng 8 on hub 0 nov 29 13:02:38 ltguido23 kernel: amdgpu 0000:63:00.0: amdgpu: ring comp_1.1.1 uses VM inv eng 9 on hub 0 nov 29 13:02:38 ltguido23 kernel: amdgpu 0000:63:00.0: amdgpu: ring comp_1.2.1 uses VM inv eng 10 on hub 0 nov 29 13:02:38 ltguido23 kernel: amdgpu 0000:63:00.0: amdgpu: ring comp_1.3.1 uses VM inv eng 11 on hub 0 nov 29 13:02:38 ltguido23 kernel: amdgpu 0000:63:00.0: amdgpu: ring sdma0 uses VM inv eng 12 on hub 0 nov 29 13:02:38 ltguido23 kernel: amdgpu 0000:63:00.0: amdgpu: ring vcn_unified_0 uses VM inv eng 0 on hub 8 nov 29 13:02:38 ltguido23 kernel: amdgpu 0000:63:00.0: amdgpu: ring jpeg_dec uses VM inv eng 1 on hub 8 nov 29 13:02:38 ltguido23 kernel: amdgpu 0000:63:00.0: amdgpu: ring mes_kiq_3.1.0 uses VM inv eng 13 on hub 0 nov 29 13:02:38 ltguido23 kernel: amdgpu 0000:63:00.0: amdgpu: recover vram bo from shadow start nov 29 13:02:38 ltguido23 kernel: amdgpu 0000:63:00.0: amdgpu: recover vram bo from shadow done nov 29 13:02:38 ltguido23 kernel: amdgpu 0000:63:00.0: amdgpu: GPU reset(4) succeeded! nov 29 13:02:38 ltguido23 kernel: [drm:amdgpu_cs_ioctl [amdgpu]] *ERROR* Failed to initialize parser -125! nov 29 13:02:38 ltguido23 org.mozilla.firefox.desktop[4257]: [GFX1-]: Detect DeviceReset DeviceResetReason::DRIVER_ERROR DeviceResetDetectPlace::WR_POST_UPDATE in Parent process
Although not a serious issue I can work around, I am interested to find the root cause of this issue. Would that be FF, or the AMDGPU modules? Or a combination. Is there anything I can log in FF when this happends? FYI, system is fully up-to-date.
Alle svar (1)
Please follow the steps below to provide us crash IDs to help us learn more about your crash.
The crash report is several pages of data. We need the report numbers to see the whole report.
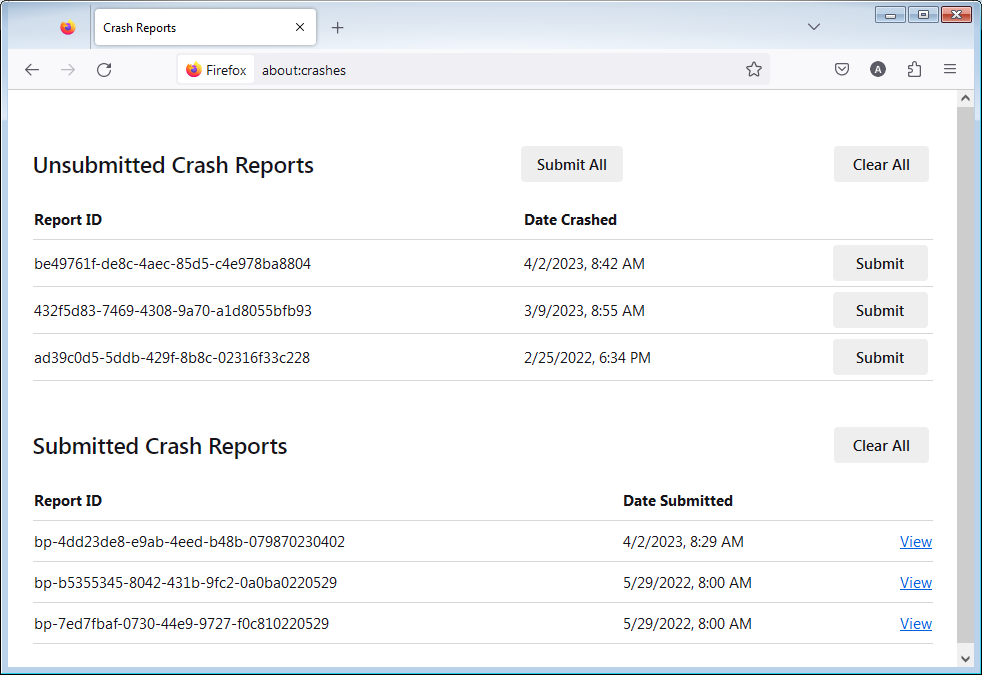
- Enter about:crashes in the Firefox address bar and press Enter. A list of Submitted (and Unsubmitted, if any) Crash Reports will appear, similar to the one shown below.
- Copy the 5 most recent Submitted Report IDs that start with bp- and then go back to your forum question and paste those IDs into the "Post a Reply" box.
Note: If a recent Report ID does not start with bp- click on it to submit the report.
(Please don't take a screenshot of your crashes, just copy and paste the IDs. The below image is just an example of what your Firefox screen should look like.)
Thank you for your help!